This document outlines the procedure for converting RichText data managed within the WordPress content area into Portable Text format for use as Sanity content.
Converting HTML to Portable Text
2025-11-09
Official documentation can be found at the following site.
Convert HTML to Portable Text
In HTML managed by WordPress, there is a concept called blocks, and it is necessary to process that data. The procedure involves implementing the following steps.
- Accept a string of HTML
- Convert it into Portable Text
- If it finds a figure tag, it stores the URL in an
externalImageblock - Then, in a throttled array of async functions, searches the WP REST API for that image based on its filename
- If found, either use an existing image in the in-memory cache or upload the image
- Eliminates empty blocks
- Returns the Portable Text
If the API is available, please refer to the official script. Here, we will introduce an implementation that references the asset information in the exported XML file.
Retrieve the ID from the URL
When retrieving URLs from WordPress content, you need to extract the ID from the URL to identify the asset and proceed with processing. Therefore, please add the following code to the file migrations/import-wp/lib/wpImageFetchXML.ts.
migrations/import-wp/lib/wpImageFetchXML.ts
The code above allows you to retrieve the Post ID from an image URL.
Schema Update
When executing the script used this time, errors occur due to some missing schemas: sanityImageHotspot and sanityImageCrop. Add the schema definitions to the schemaTypes/index.ts file. The file after the addition is as follows.
schemaTypes/index.ts
Retrieving HTML
Add the following code as a script to retrieve HTML data in the file `./migrations/import-wp/lib/htmlToBlockContent.ts`. This code has been rewritten to read files from XML and upload them, so it differs from the official code. The console.log code used during functionality testing has also been commented out.
./migrations/import-wp/lib/htmlToBlockContent.ts
The code above is missing packages, so run the following command to add them.
sh
Reflect in the post's content
To process the acquired data as wpDoc.content, update ./migrations/import-wp/lib/transformToPost.ts as follows.
./migrations/import-wp/lib/transformToPost.ts
Reflect the data
You are now ready to place the HTML data into the Content. Please execute the following command.
sh
Upon checking the results, images were retrieved from WordPress and the content was updated to include them.
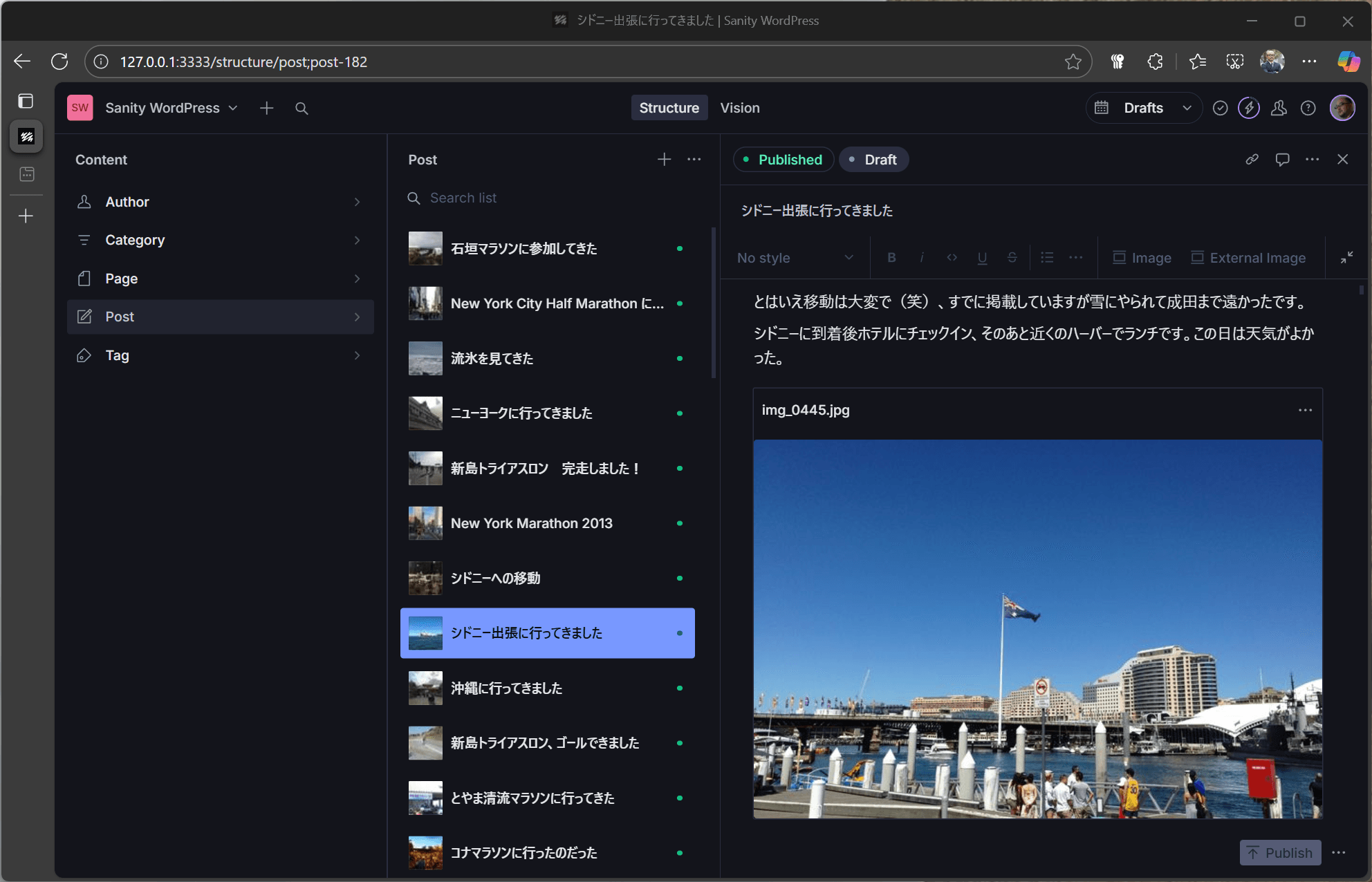
Convert WordPress blocks to portable text
Regarding this article, since the blog I currently maintain does not utilize WordPress blocks, verification will be omitted. As stated at the beginning, the following page contains the official procedure.
About Column Blocks
WordPress has a feature called the Column Block. It allows you to create multiple rows within a page and place content in each one. Using this, you can arrange content such as an image on the left and rich text on the right. Since this isn't achieved using rich text alone, you need to process the Column Block data in some way.
The article above outlines the steps to add a custom type that can accept data from a column block, enabling the use of that data in Portable Text.
The serialization procedure for acquiring this data and the migration script update procedure are also documented. The final result will be as follows.
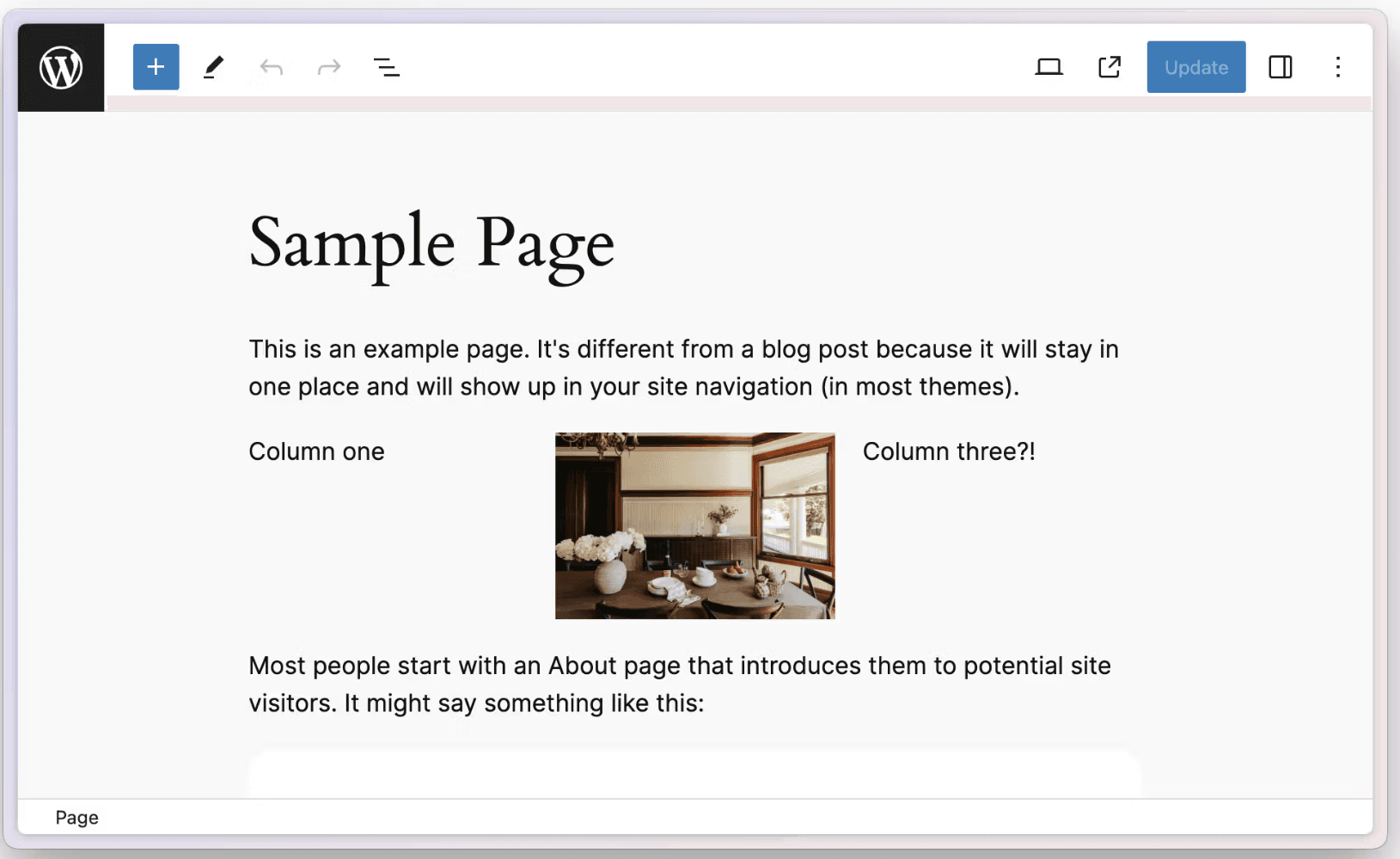
Regarding custom content types, I'll share some samples at a later date. For now, the purpose is migration, and I introduced this section to help you understand the procedure.
Summary
I've successfully migrated all my blog posts. Since I only transferred the HTML data and images, internal links will naturally work as long as the URLs haven't changed. However, I'd like to add extensions like automatic link creation. I plan to cover that part in a future post.
The code up to this point is publicly available in the branch of the following repository.
Finally, let's proceed with migrating the Page data, not the Posts.